Custom Machine Learning Models
Architect custom machine learning models with FNA Technology. Read our production benchmarks, mathematical formulations, and engineering pricing.
Get Started Today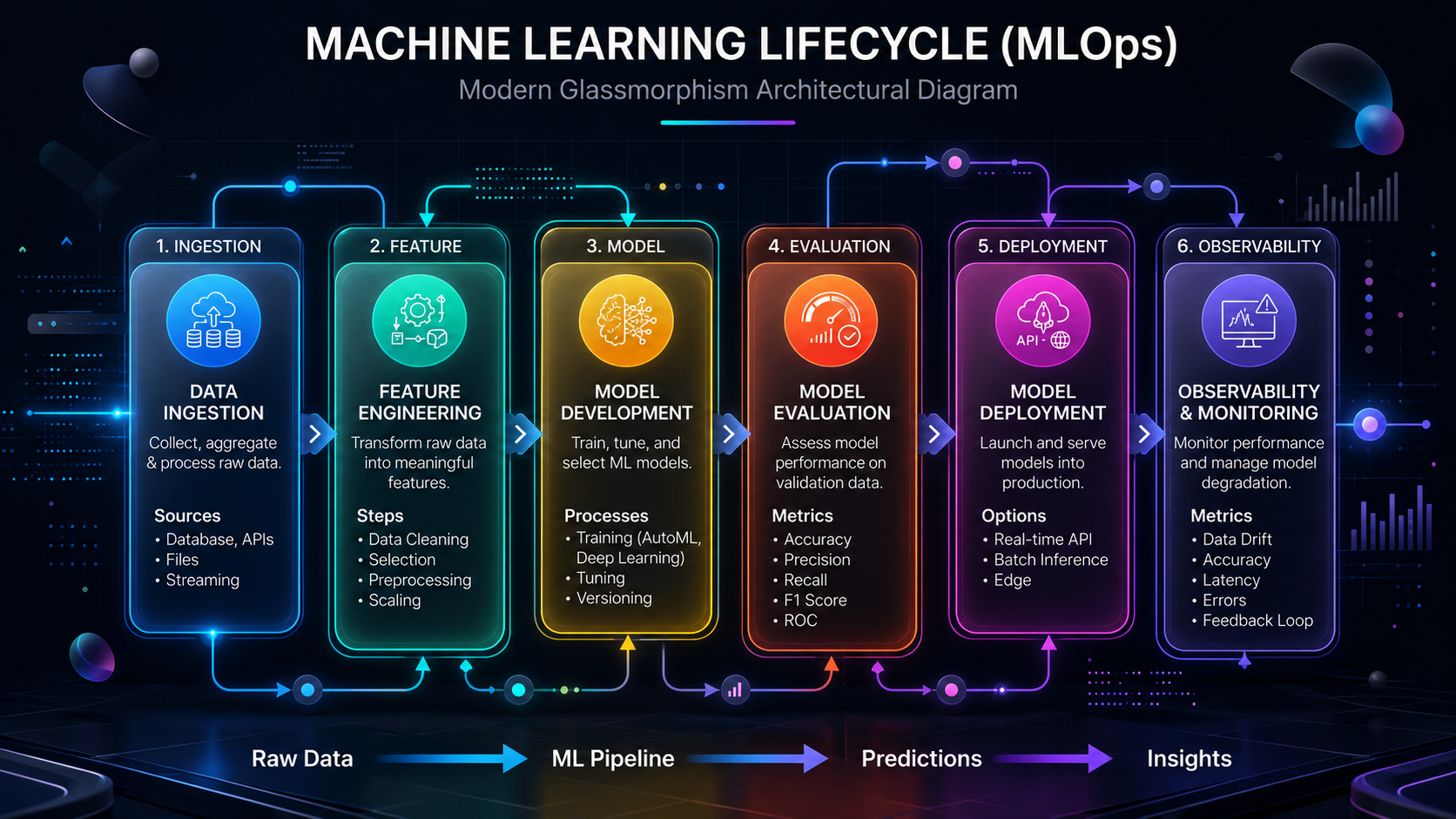
Custom machine learning models are bespoke mathematical algorithms trained on specialized enterprise datasets to solve specific classification, prediction, or generation tasks. Unlike generic, off-the-shelf APIs, these proprietary systems are optimized for your business metrics, schema definitions, and hardware constraints. FNA Technology designs, trains, and deploys these models entirely in-house, connecting them directly into your production software to automate complex decisions with high statistical accuracy.
How does FNA Technology engineer custom machine learning models?
FNA Technology coordinates a structured six-stage lifecycle framework that ensures predictability, statistical validation, and operational stability. This consultative engineering process places your technical leaders in direct collaboration with our senior machine learning engineers, removing intermediate management layers to accelerate development.
The lifecycle spans from raw data ingestion to active runtime observability, as detailed in the technical blueprint below:
The FNA Technology Machine Learning Lifecycle (FML-6)
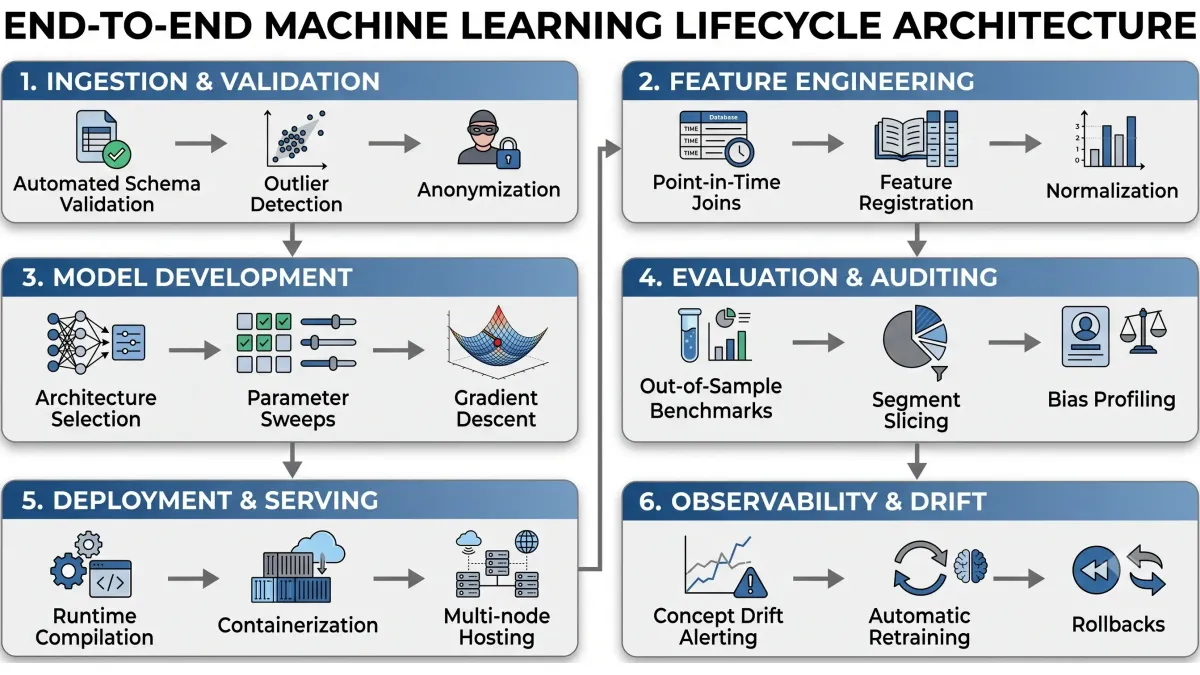
| Lifecycle Stage | Core Technical Processes | Primary Validation Metrics |
|---|---|---|
| 1. Ingestion & Validation | Schema validation, duplicate removal, outlier detection, data anonymization | Batch success rate, ingestion latency, null value rate |
| 2. Feature Engineering | Mathematical normalization, feature scaling, missing-value imputation | Preprocessing latency, feature drift scores, calculation overhead |
| 3. Model Development | Model architecture selection, distributed parameter sweeps | Training loss, validation loss, learning rate decay |
| 4. Evaluation & Auditing | Out-of-sample benchmarking, segment slicing, fairness profiling | Accuracy, Precision, Recall, F1-Score, ROC-AUC, RMSE |
How does FNA Technology prevent training-serving skew?
Training-serving skew occurs when the mathematical features supplied to a model during training differ from those evaluated during real-time inference. Inconsistencies typically arise from differences in offline and online data transformation logic or from temporal data leakage.
FNA Technology mitigates this operational risk by deploying the Feast Feature Store as an abstraction layer between raw data pipelines and the machine learning models. The feature store decouples feature engineering from model consumption, ensuring that identical data definitions are utilized across all environments.
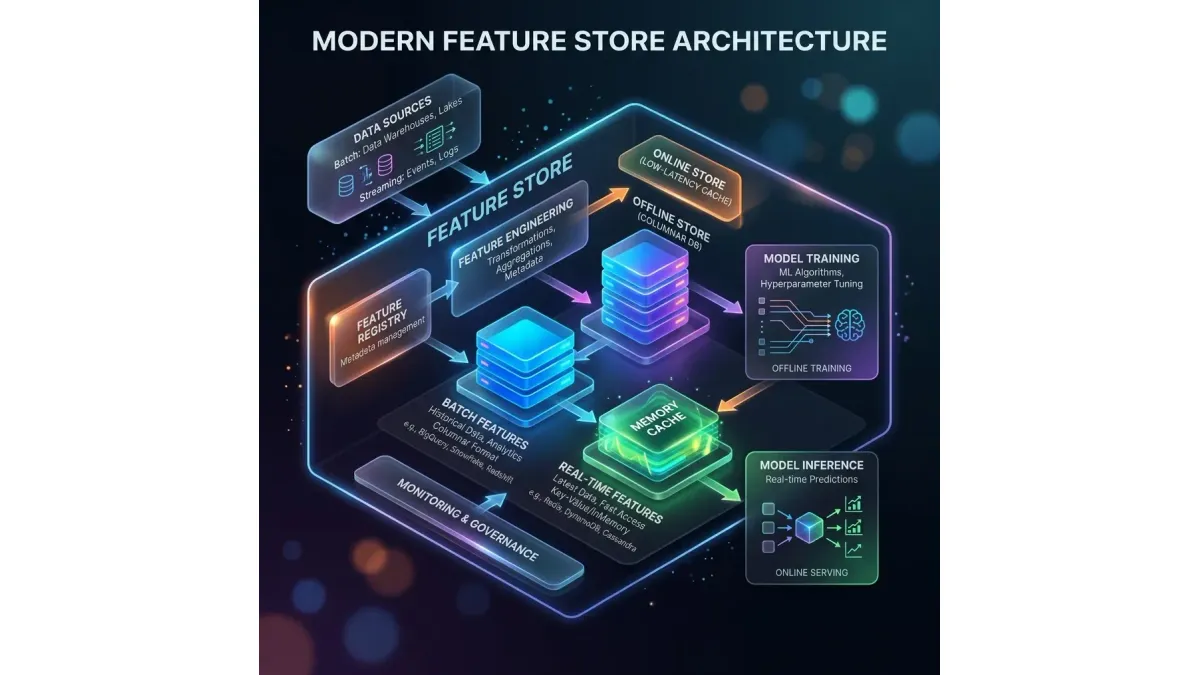
The storage architecture of the feature store is split into two complementary tiers to support distinct computational requirements:
- The Offline Feature Store: This component manages historical, time-series feature data in a columnar format like BigQuery, Snowflake, or AWS Redshift. It is optimized for large-scale batch queries used in model training.
- The Online Feature Store: This component relies on low-latency, row-oriented databases like Redis or DynamoDB to store only the latest pre-computed feature values for each entity.
How does hybrid search combine BM25 and vector embeddings?
In the retrieval stage of generative and question-answering systems, relying solely on semantic vector search often degrades performance when queries contain exact keywords, part numbers, or system codes. To resolve this, FNA Technology implements a parallel retrieval architecture that combines lexical keyword search (BM25) and dense vector search, consolidating the outputs through Reciprocal Rank Fusion (RRF).
Mathematical Aggregation via Reciprocal Rank Fusion
Reciprocal Rank Fusion (RRF) bypasses score normalization issues by disregarding the raw scores returned by each system, focusing instead on the ordinal rank of each document within the respective result sets. The final RRF score for a document across a set of retrieval models is calculated as:
- represents the set of retrieval systems, including BM25 and vector search.
- is the ordinal rank of document within the results of retrieval system .
- is a constant hyperparameter (typically configured to ).
How does Low-Rank Adaptation lower fine-tuning memory costs?
When deploying generative models for specialized domain tasks, standard prompting often falls short of strict formatting requirements. While Full Fine-Tuning (FFT) modifies all weights in a network, it is computationally expensive and requires multiple high-end GPUs. FNA Technology utilizes Parameter-Efficient Fine-Tuning (PEFT), primarily leveraging Low-Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (QLoRA), to enable cost-effective adaptation.
Mechanics of Low-Rank Adaptation
LoRA freezes the pre-trained weights of the base model () and updates the network by factorizing the weight update matrix into two low-rank matrices, and . The rank hyperparameter is configured such that .
During forward propagation, the mathematical operation is expressed as:
How does PatchTST execute time-series prognostic modeling?
Custom machine learning models are widely applied in industrial predictive maintenance to analyze streaming sensor telemetry, detect operational anomalies, and forecast the Remaining Useful Life (RUL) of high-value machinery. Standard sequence models struggle to capture long-range temporal dependencies in high-frequency sensor streams.
Additionally, standard Transformer architectures suffer from quadratic computational complexity () relative to the input sequence length , limiting their scalability on long look-back windows.
To resolve these computational limitations, FNA Technology deploys PatchTST (Patch Time Series Transformer). PatchTST introduces two structural paradigms designed for time-series data:
- Patch-Level Tokenization: Rather than feeding individual, pointwise time steps into the attention mechanism, PatchTST aggregates adjacent time steps into continuous, overlapping patches of size . This patching strategy reduces the self-attention computational complexity from to , enabling the model to process significantly longer look-back windows without memory saturation.
- Strict Channel Independence: In multivariate sensor environments, the input stream is decomposed into independent, univariate sequences.
The model is optimized using Mean Squared Error (MSE) calculated over the forecast target window:
How much does a custom machine learning model cost?
The financial investment required to build a custom machine learning model depends on the engineering complexity, data preparation scale, and serving infrastructure targets. FNA Technology structured implementations range from standard prediction engines to deep neural architectures:
- Focused Prediction or Classification Engines: These systems process tabular data or structured transaction records for forecasting and scoring. Development cycles span 4 to 8 weeks, with budgets ranging from $15,000 to $30,000.
- Generative AI & Specialized LLM Customizations: These systems combine hybrid retrieval pipelines, vector databases, and parameter-efficient fine-tuning (LoRA/QLoRA) on domain-specific corpora. Execution spans 6 to 12 weeks, with budgets ranging from $35,000 to $65,000.
- Complex Time-Series Prognostics or Spatial Routing: These high-density industrial architectures ingest multivariate sensor streams or spatial graphs (e.g., PatchTST, routing clustering). Development takes 12 to 16 weeks, with budgets ranging from $70,000 to $120,000.
FNA Technology Enterprise AI Delivery Framework
FNA Technology designs, builds, and deploys intelligent systems entirely in-house. Our software development studio works directly with startup, SME, and enterprise leaders to ship high-performance digital platforms across the United Kingdom, India, the United Arab Emirates, and North America.
By removing intermediate management layers and account managers, we ensure that clients work directly with the senior machine learning engineers building their models. If you have an active project in mind or want to evaluate your data readiness, contact our engineering team to map your architecture.