Generative AI & LLM Engineering
Architect production-grade Generative AI applications. Explore our technical methodologies for Advanced RAG, QLoRA fine-tuning, and deterministic Agentic Workflows.
Architect Your System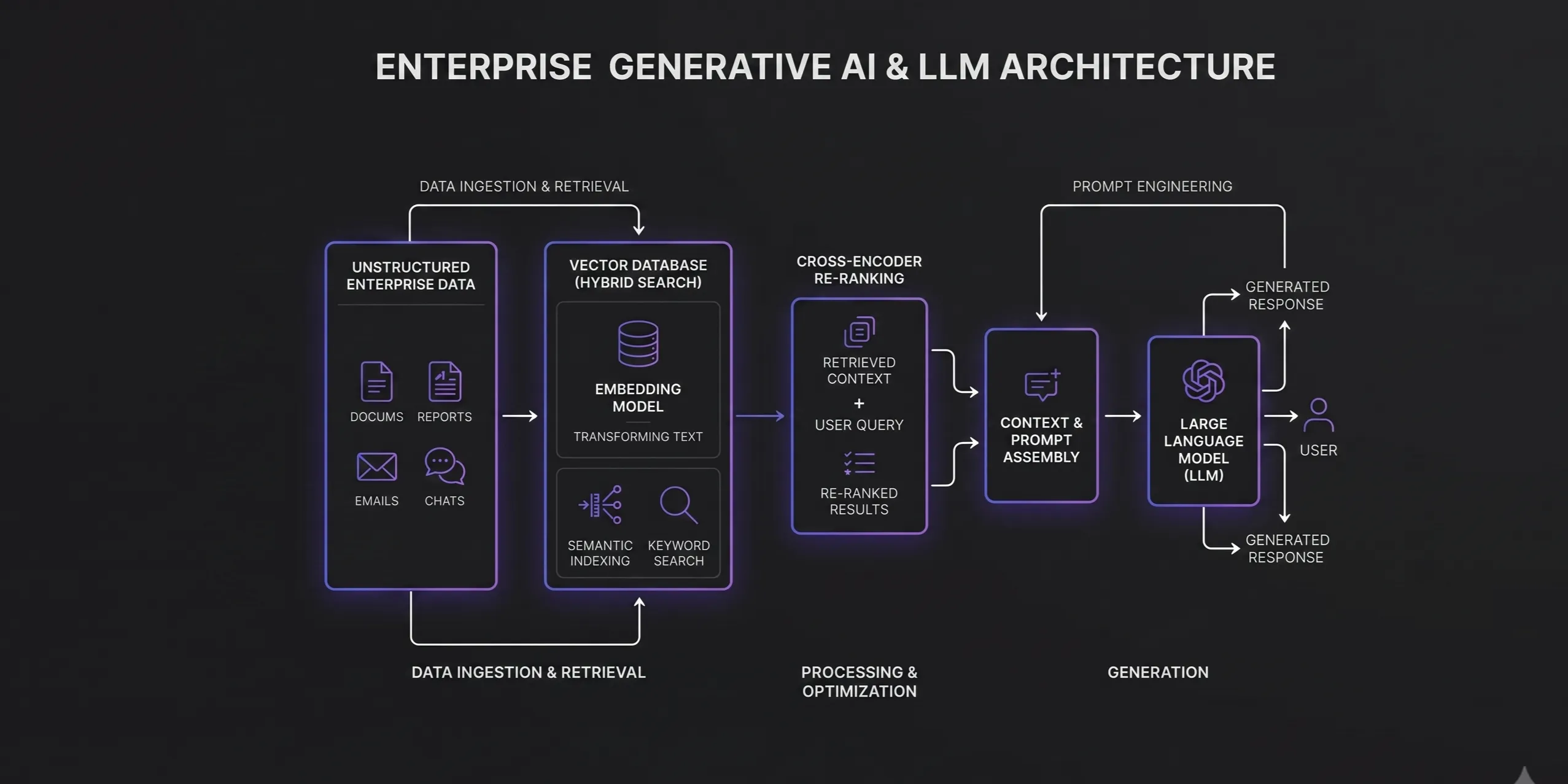
Deploying Large Language Models (LLMs) in a commercial environment extends far beyond API wrapping. Enterprise Generative AI demands strict determinism, sub-second latency targets, and robust data isolation. FNA Technology architects end-to-end LLM applications, specializing in Advanced Retrieval-Augmented Generation (RAG), Parameter-Efficient Fine-Tuning (PEFT), and deterministic Agentic orchestration systems.
Advanced RAG: Grounding Generation in Enterprise Context
Standard naive RAG models often fail in production due to context dilution—injecting irrelevant chunks into the LLM's finite context window. To solve this, FNA Technology deploys Advanced RAG architectures that utilize multi-stage retrieval pipelines.
We begin with document parsing and semantic chunking, converting unstructured enterprise data into dense vector embeddings. Retrieval relies on Hybrid Search, blending dense embeddings (via Cosine Similarity) for semantic intent with sparse lexical representations (BM25) for precise keyword matching.
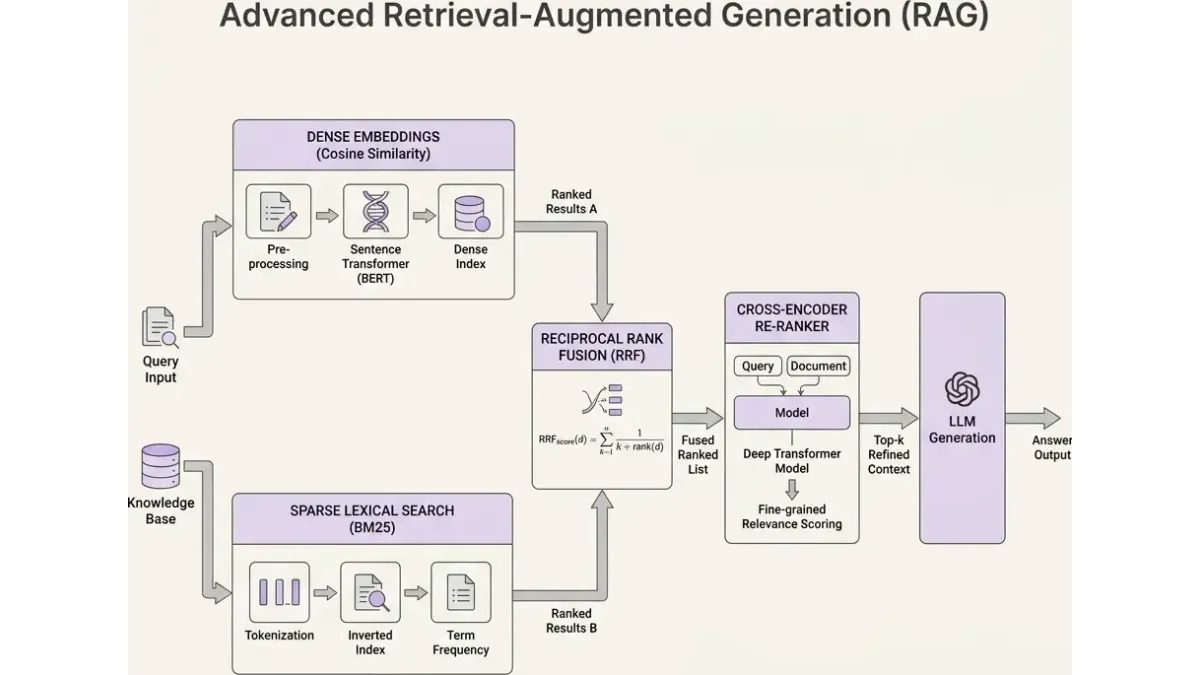
Mathematical Foundation of Vector Retrieval
Dense retrieval calculates the distance between the embedded query vector and document chunk vectors using Cosine Similarity, maximizing the dot product of normalized vectors:
Mitigating Context Dilution via Cross-Encoder Re-Ranking
After retrieving the top- documents from the vector database, we apply a Cross-Encoder re-ranking model. Unlike Bi-Encoders used for initial retrieval, Cross-Encoders process the query and document simultaneously through the Transformer layers, computing deep cross-attention. This drastically improves precision, ensuring only the most relevant context chunks are injected into the final generator LLM prompt.
QLoRA: Parameter-Efficient Fine-Tuning
When foundational models fail to capture specific industry dialects (e.g., legal phrasing, medical taxonomy) or structural syntaxes (e.g., proprietary JSON formats), we employ Quantized Low-Rank Adaptation (QLoRA) to fine-tune open-weight models (like Llama 3) efficiently.
QLoRA quantizes the base model weights to 4-bit NormalFloat (NF4), drastically reducing VRAM requirements. During backward propagation, only the low-rank adapter matrices ( and ) receive gradient updates, keeping the base model frozen. The total weight update is expressed as:
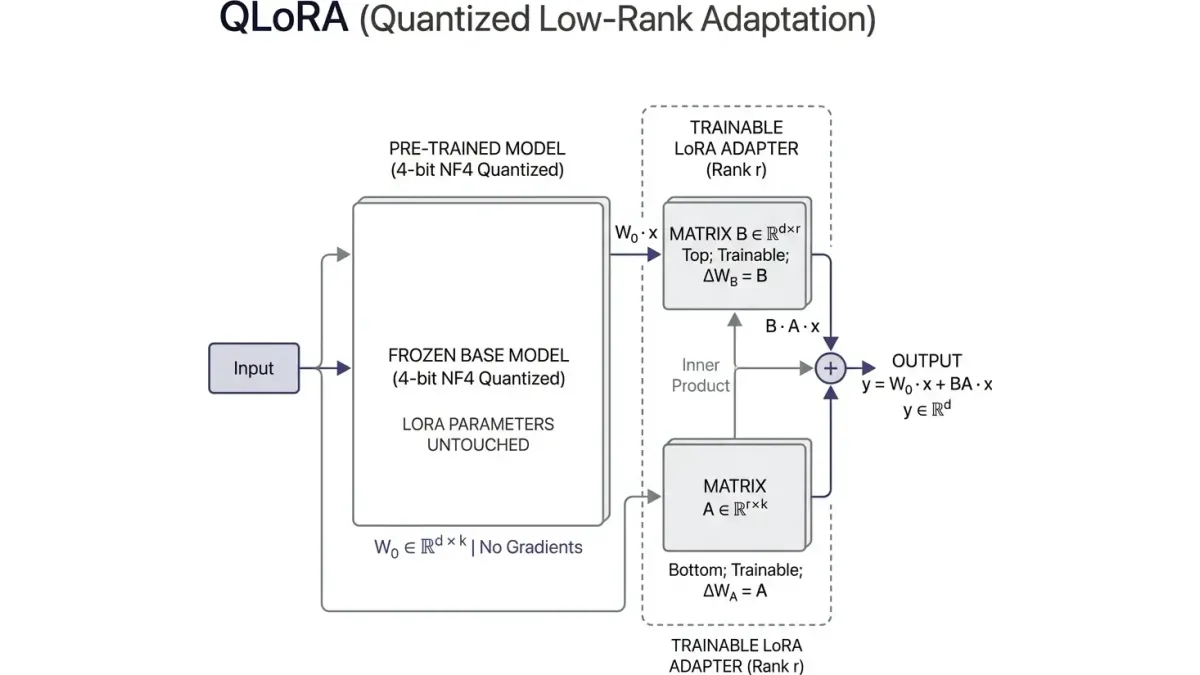
- : Frozen 4-bit quantized base weights.
- : Trainable low-rank matrices where rank .
Agentic Workflows & The ReAct Paradigm
Transitioning from passive chatbots to active, autonomous systems requires Agentic Workflows. FNA Technology builds agents that possess the ability to invoke external tools (APIs, SQL databases, calculators) to augment their capabilities. We implement the ReAct (Reasoning and Acting) paradigm, forcing the LLM to output its internal trace before executing a tool.
The ReAct loop operates in continuous cycles of Thought Action Observation. By enforcing this determinism, agents can resolve complex, multi-step tasks without derailing into infinite loops or hallucinations. For complex systems, we deploy multi-agent orchestration frameworks (like LangGraph) where specialized agents route tasks among themselves.
Production LLM Evaluation & Guardrails
"Vibes" are not a viable metric for production. We implement rigorous, programmatic evaluation pipelines utilizing the RAGAS framework. During CI/CD, synthetic datasets are used to score the architecture across vital dimensions:
| Evaluation Metric | Measurement Goal | Impact |
|---|---|---|
| Faithfulness | Measures if the generated answer is entirely inferable from the retrieved context. | Directly quantifies hallucination rates. |
| Answer Relevance | Scores how directly the generated answer addresses the user's initial query. | Prevents tangential or evasive responses. |
| Context Precision | Evaluates whether the most relevant chunks were ranked highest. | Validates the effectiveness of the Re-ranker. |
Engineering Pricing & Engagement
Our Generative AI solutions are engineered to order. Pricing is dictated by the complexity of the data ingestion pipelines, the necessity for custom fine-tuning, and the depth of system integrations.
- Advanced RAG Pipelines: Knowledge extraction from standard enterprise formats (PDF, Confluence) with hybrid search and guardrails. Typical execution spans 4 to 8 weeks, ranging from $25,000 to $45,000.
- Agentic Orchestration Systems: Multi-agent ReAct workflows deeply integrated into core APIs (e.g., Salesforce, SAP) capable of autonomous execution. Execution spans 8 to 14 weeks, ranging from $60,000 to $95,000.
- On-Premise / Open-Weight Deployments: Secure deployment of fine-tuned open models (Llama, Mistral) on dedicated GPU clusters using vLLM for data sovereignty. Scoped independently based on infrastructure requirements.